| Distributed systems offer fantastic gains when it comes to solving large-scale problems. By sharing the computation load, you can solve problems too large for a single computer to handle, or solve problems in a fraction of the time it would take with a single computer. The Grid Computing Toolbox has been streamlined for Maple 15, making it easy to create and test parallel distributed programs. New features include a simplified local grid setup, flexible argument passing, and an extended API. |
|
Compatible with Maple 15 Local Grid API
Maple 15 includes the ability to easily set up multi-process computations on a single computer. The Maple Grid Computing Toolbox extends this power to multi-machine or cluster parallelism. The two versions are fully compatible, so that an algorithm can be created and fully tested using the local implementation inside Maple, and then deployed to the full cluster using the toolbox, without changes to the algorithm.
Flexible Argument Passing
The Launch command can now process multi-argument procedures and automatically pass those parameters to each of the nodes in the grid. This avoids the need to work with global data referenced by the 'exports' option.
Getting data to each node can be done in two ways using the Launch command.
• Arguments to the called procedure can be passed as arguments to the Launch command.
• Other data can be specified using the 'imports' option to Launch |
Also, once the computation has been started, Send and Receive can be used for passing chunks of data to each individual node.

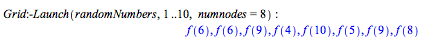
Above, the range, 1..10, is passed as an argument to the execution of randomNumbers on each node. The custom function, f, is not defined so it returns unevaluated. You can set a value for f, and use the 'imports' option to pass that value to all of the nodes.
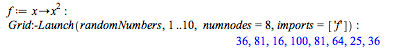

Extended API
A Barrier command has been added to the Grid package. This is useful as a checkpoint to ensure all grid nodes stop and sync up before proceeding. A key spot to use Barrier is at the end of a program that does not use any message passing. Using it forces node 0 to wait until all working nodes complete their activity before returning.
Example 1: Monte Carlo Integration
Random values of x can be used to compute an approximation of a definite integral according to the following formula.
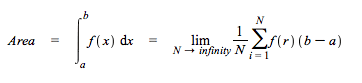
This procedure efficiently calculates a one-variable integral using the above formula where r is a random input to f.

A sample run using 1000 data points shows how this works:

This can be computed exactly in Maple to show the above approximation is rough, but close enough for some applications.

A parallel implementation adds the following code to split the problem over all available nodes and send the partial results back to node 0. Note that here the head node, 0, is used to accumulate the results, and does not actually do any computations.

Integrate over the range, lim, using N samples. Use as many nodes as are available in your cluster.
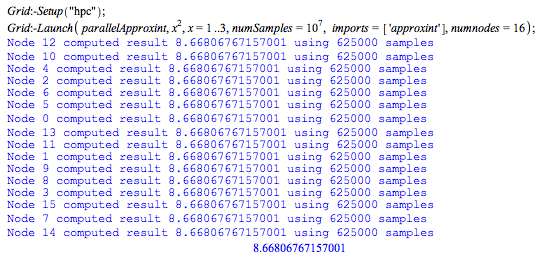
Execution times are summarized as follows. Computations were executed on a 3-blade cluster with 6 quad-core AMD Opteron 2378/2.4GHz processors and 8GB of memory per pair of CPUs, running Windows HPC Server 2008.
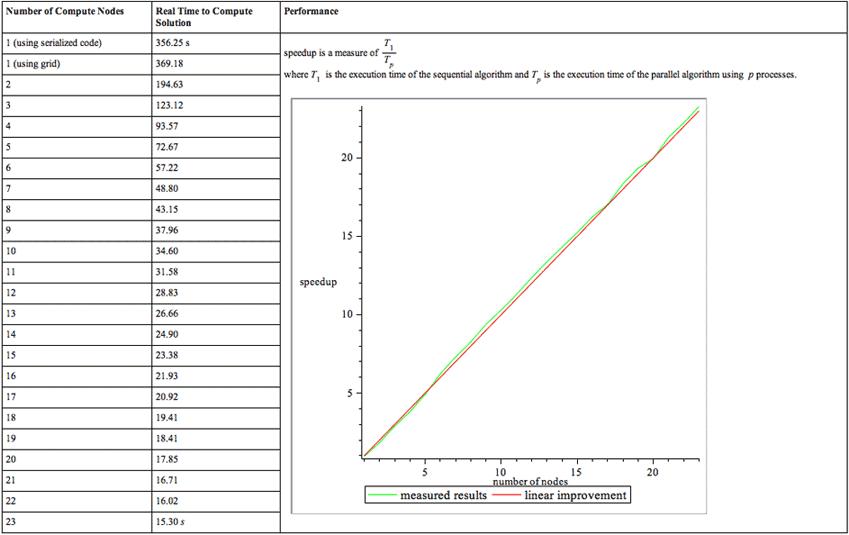
The compute time in Maple without using MapleGrid is the first number in the table -- ~6 minutes. The rest of the times were using MapleGrid with a varying number of cores. The graph shows that adding cores scales linearly. When 23 cores are dedicated to the same example, it takes only 15.3 seconds to complete.
|

