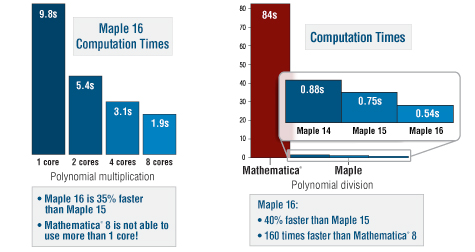
Polynomial arithmetic Over the past couple of releases, the efficiency of polynomial arithmetic in Maple has been improved dramatically:
This has been achieved through a combination of various techniques:
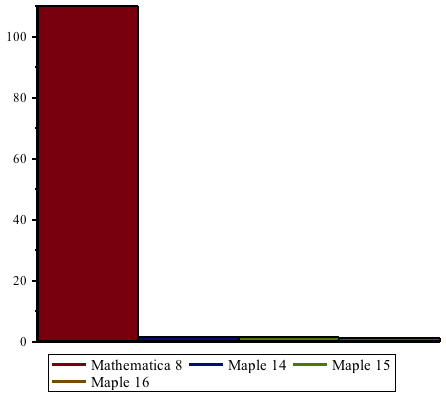
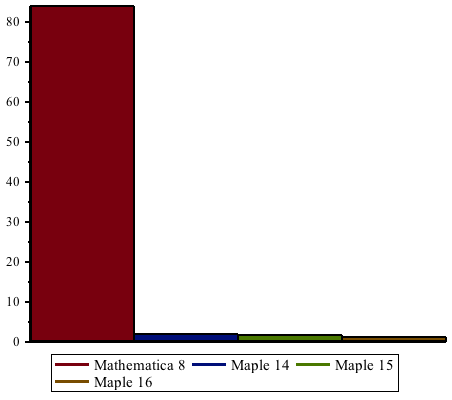
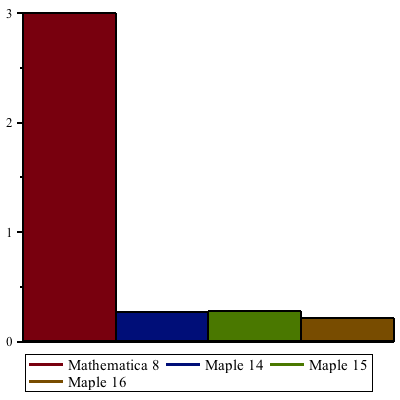
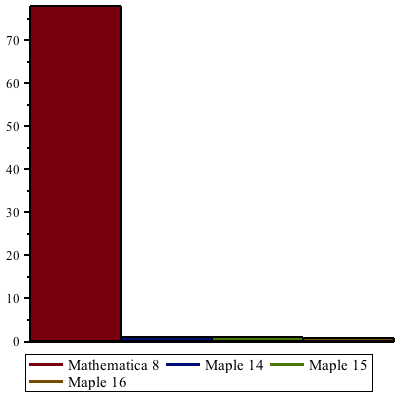
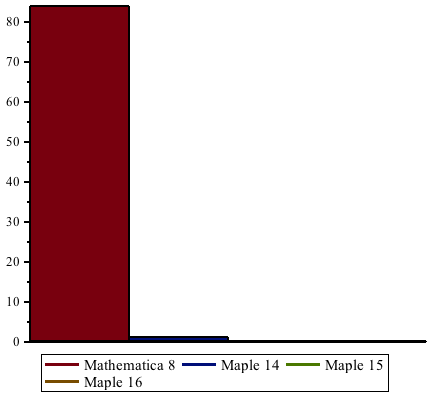
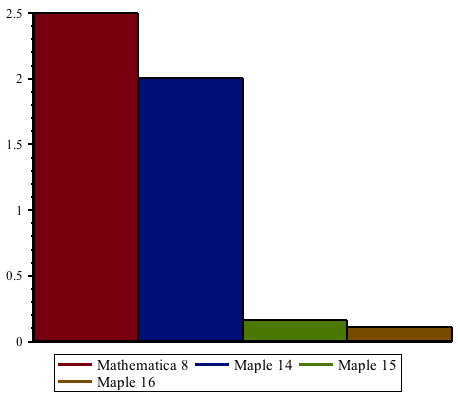
Improvements in Maple 16 have increased speed-ups even further since Maple 15, by more than a factor of 2. Maple 16 is up to 22 times faster than Maple 14 and earlier when performing these computations, and up to 1800 times faster compared to Mathematica® 8.
Maple has two commands for polynomial factorization, i.e., the multiplicative decomposition of a multivariate polynomial into irreducible factors that cannot be decomposed any further.
Note that the resulting factors have integer coefficients as well. For example,
In the most general case, the polynomial can have more than one variable and may already contain non-rational expressions such as
In Maple 16, the computational efficiency of the evala(Factor(...)) command has been improved dramatically, particularly in the presence of multiple and nested RootOfs. The speedup is due to a new and efficient sparse modular algorithm. For example, the execution time for the following example is about 20 times faster than in Maple 15 on the same machine.
The following table shows some benchmarks in comparison to Maple 15.
Polynomial ideal decomposition A generalization of the concept of factoring a single polynomial into its multiplicatively irreducible factors is the prime decomposition of a polynomial ideal, generated by a finite set of multivariate polynomials. Maple's PolynomialIdeals package provides, in addition to many useful commands and tools for manipulating and analyzing polynomial ideals, the PrimeDecomposition command, as well as the Radical command, which computes equivalent to the squarefree part for a polynomial ideal. The computational efficiency of these two commands was improved for Maple 16, leading to dramatic speedup factors of more than 700 in some cases.
The following table shows some benchmarks in comparison to Maple 15.
Bernoulli Numbers Bernoulli numbers are a sequence of rationals that are important in number theory and in particular for the Euler-Maclaurin formula. Maple is able to compute Bernoulli numbers very efficiently:
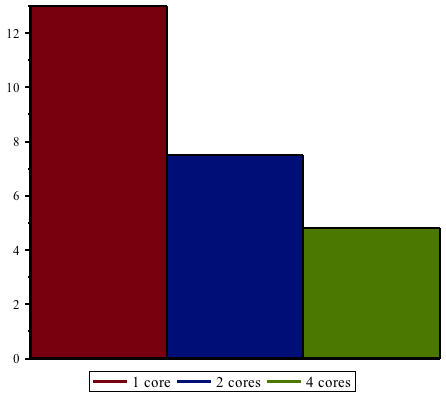
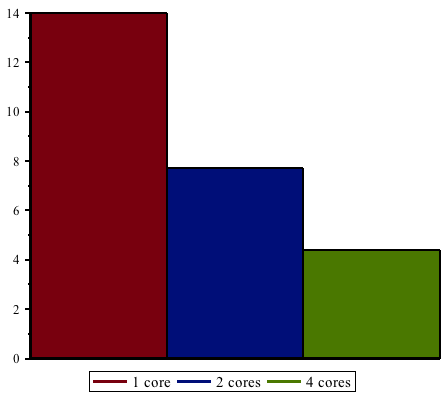
Maple 16 is able to take advantage of multi-core machines to compute sequences of Bernoulli numbers in parallel:
Numeric linear algebra The compiled C version (CLAPACK) of the LAPACK numerical linear algebra library used and shipped with Maple has been upgraded to version 3.2.1. Algorithms used for nonsymmetric eigen-solving have been markedly improved. For example, the time to compute all eigenvectors of a size 1000x1000 random nonsymmetric hardware float Matrix, has decreased from 30.1 seconds in Maple 15 to 11.6 seconds in Maple 16 (AMD X2 4600+ 64bit Linux)
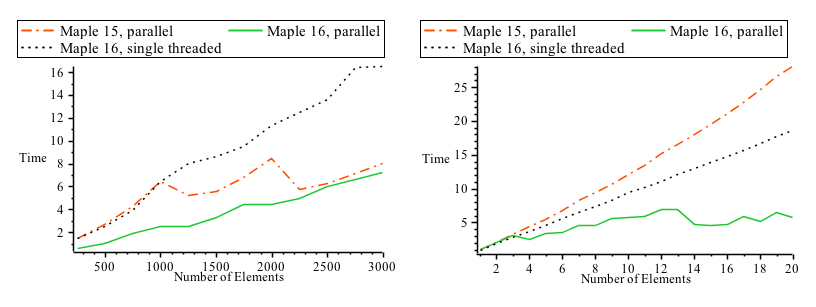
Maple offers parallel implementations of the powerful map, seq, add and mul commands in the Threads package. These commands automatically parallelize over the available core for each operation and yield significant speed ups with very little user effort. The heuristic used to automatically determine how to split up the computation among the cores has been dramatically improved in Maple 16. The following charts show the behavior of Maple 15 vs. Maple 16 on two example problems, one with a large number number of short computations and one with a smaller number of long-running computations.
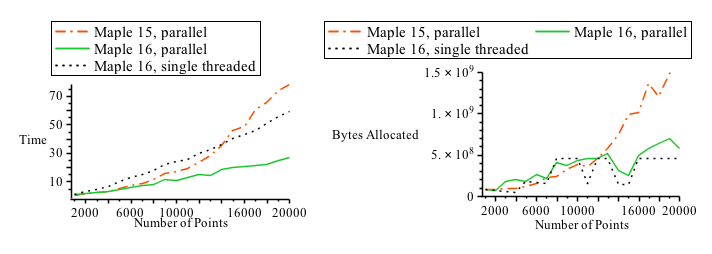
In addition to a better automated heuristic, Maple 16 also offers direct user control about how to split such computations up across cores with the new tasksize option. Memory management Automatic memory management alleviates a programmer from the low-level details of allocating and deallocating storage space for the results of their computation. This enables programmers to concentrate on developing correct and efficient high-level algorithms to solve their problems.Significant improvements have been made to both the memory allocator and garbage collector that together comprise Maple's memory management system. The modernization of the memory management system positions Maple to effectively use the resources available on not only the machines of today but also those of tomorrow. For example, the advances in CPU performance will continue to be driven by the increase in the number of cores per chip. Matching this trend, the advances to both the memory allocator and garbage collector are primarily centered around simultaneously handling the memory demands of multiple threads running on multi-core machines. Furthermore, Maple 16 is able to more effectively use the larger amounts of memory available on 64-bit architectures.These memory management enhancements will improve the computation time of any large or memory-intensive operations throughout Maple. The following charts illustrate the gains derived from the new memory manager on a parallel convex hull example:
Grid computing Distributed systems offer fantastic gains when it comes to solving large-scale problems. By sharing the computational load, you can solve problems too large for a single computer to handle, or solve problems in a fraction of the time it would take with a single computer. The Maple Grid Computing Toolbox platform support has been extended for Maple 16, making it easy to create and test parallel distributed programs on some of the world's largest clusters. MPICH2 is a high performance implementation of the Message Passing Interface (MPI) standard, distributed by Argonne National Laboratory (http://www.mcs.anl.gov/research/projects/mpich2/). The stated goals of MPICH2 are to:
The Grid Computing Toolbox for Maple 16 now includes the ability to easily set up multi-process computations that interface with MPICH2 to to deploy multi-machine or cluster parallel computations. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
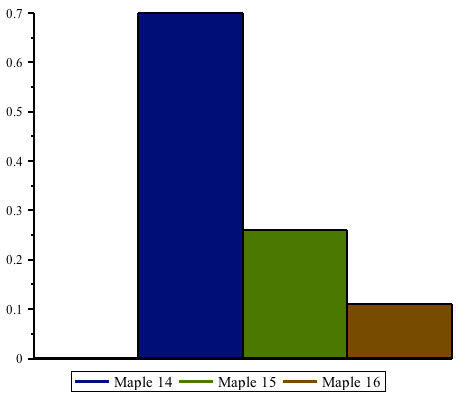
](/products/maple/new_features/images16/ComputationalEfficiency_178.gif)
, Vector[column](%id = 18446744078138800718)](/products/maple/new_features/images16/ComputationalEfficiency_180.gif)