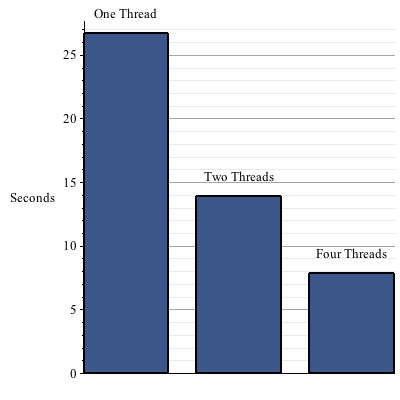
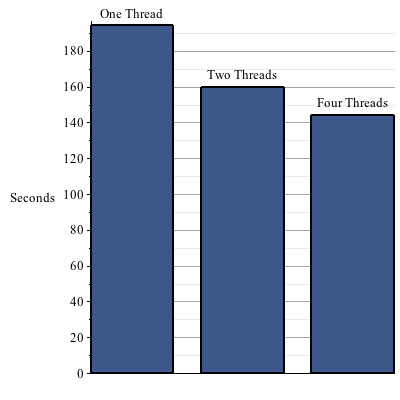
Maple 17 introduces parallelism into its memory management system, taking advantage of multiple processors to perform its job more quickly. This change can lead to a reduction of running times for all computations, not just parallel algorithms. With no code changes required, your computations will run 10% faster on average, with memory-intensive computations running up to 50% faster. In addition, new programming constructs were added to make it easier to write parallel code. Variables and procedure remember tables can be declared local to the thread, so that each instance can store different values. This allows for complex algorithms that need to maintain state to be written in a thread-safe manner. Details and Examples One of the core components of Maple's engine is the 'garbage collector'. The garbage collector is responsible for finding and reclaiming memory that is no longer needed by the evaluation engine. In Maple 17, the garbage collector is capable of taking advantage of multiple processors to perform its job more quickly. As the garbage collector is used continuously as Maple runs, this speed up helps all users, not just those running parallel algorithms.
In Maple 17, procedures have different remember tables for each thread the procedure is executed on. When a procedure with a thread local remember table is executed in parallel, modifications to the remember table will not lead to thread safety issues. This change makes it easier to write thread safe functions that make use of remember tables, especially when direct manipulation of the remember table is required. A procedure with a shared remember table, one that is shared between threads, can still be created by passing option shared to the procedure. This provides the same functionality as previous versions of Maple. In Maple 17 remember tables are thread local by default. When a procedure with a remember table is called by multiple threads, the remembered results are only available on the thread that created them. The following procedures implement a sequence similar to Fibonacci, where each term is the sum of the previous two terms, however the user can specify the initial values. A remember table is used to improve the performance of this procedure. The initial values are stored in FibsHelper's remember table where they act as the termination condition for the recursion.
This works when run on a single thread, and in Maple 17, it works when run in parallel.
In previous versions of Maple, the parallel evaluation can fail. A procedure with a shared remember table (Maple's previous behavior) can still be created in Maple 17 by specifying the shared option. The following procedure will work when used in a single thread, but not in parallel.
When SharedFibs is called in parallel, incorrect results may be computed. Note that due to the nature of parallel execution, incorrect results may not occur on every run.
There are various things that can go wrong. Clearing the remember table in one thread can remove another thread's initial values, which will cause SharedFibsHelper to be called with invalid inputs (negative numbers). One threads initial values can overwrite another threads, which will cause that thread to compute incorrect results. One threads remembered values can be used by a different thread where those values are incorrect. A procedure with a shared remember table can work correctly in parallel and computed results can be shared across threads. However there are may complexities that require procedures with shared remember tables to be written with care. Maple 17's thread local remember tables makes it easier for procedure written for single threaded execution to work in parallel. In Maple 17, module local variables can be declared thread local, meaning that they store a different value for each thread that access the variable. This allows for complex algorithms that need to maintain state to be written in a thread safe manner. A module that wants to maintain internal state generally will not work correctly when executed in parallel. Consider the following example: the Mapper module maintains an internal state using the variables func and data. The setMapper routine is used to set these variables. When ModuleApply is called, it maps func over the given data.
If you execute the adder and multer commands in parallel, you can get incorrect results. Executing the following statement multiple times will show different results, some of which will be incorrect.
Incorrect results are computed because the func and data state variables are shared between threads. Thus when one thread changes func's value, the other thread is also affected. In Maple 17, this can be fixed by declaring the state variables as thread_local. This means that each thread will maintain its own value for the state variables. Thus changing the value in one thread will not effect other threads.
Executing this version, using the thread local variables, will return the expected result.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||