Maple contains a wealth of functionality for doing statistics, combining the ease of working in a high-level, interactive environment with a very large and powerful set of algorithms. Support for statistics has been further expanded in Maple 17. The new release includes:
Fitting Data for Use in a Predictive Model Maple 17 has a new algorithm for fitting data in an overdetermined system for use in predictive models. Consider a survey of large-cap Energy sector stocks in the S&P 500, where you know a lot of information about a few listings. Assume in this case that most of the data, when adjusted against general market trends, ends up being useless for predicting future markets, but some properties do end up being strong market indicators. You do not, however, know which variables to keep and which not to. Let's set up an example using random data to model this situation.
At this point we have generated the known data, and have profit numbers for that data. The following chart takes one sample parameter, property 10, and plots it against the profit. It is not obvious what the correlation is.
We want to build a model that fits all 100 properties against the data. A least-squares fit is used for comparison.
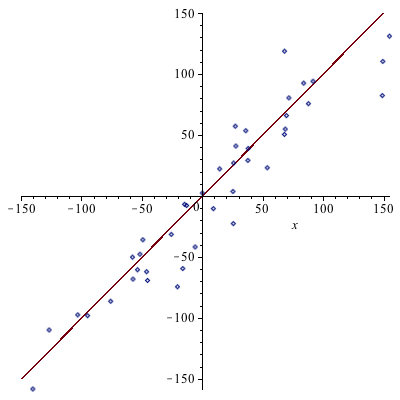
Because there are more variables than observations, we'll always get a perfect fit with 100% correlation to the existing data.
We don't really want a model that will perfectly fit today's data. We want a model that will detect which parameters are likely to actually correlate well with the profit observed and can be used in predicting new observations. We want to avoid overfitting.
Let's set up a new model using predictive least-squares.
Note that the PredictiveLeastSquares command, new in Maple 17, returns two things: the coefficient matrix (as with regular least-squares) as well as a list indicating the columns of data that it decided were most relevant for use in predicting data.
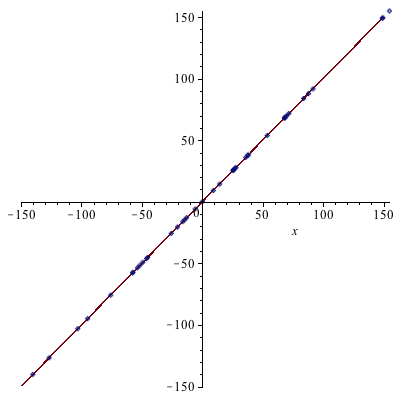
The correlation with the current profit data is not perfect (as expected) but still very good.
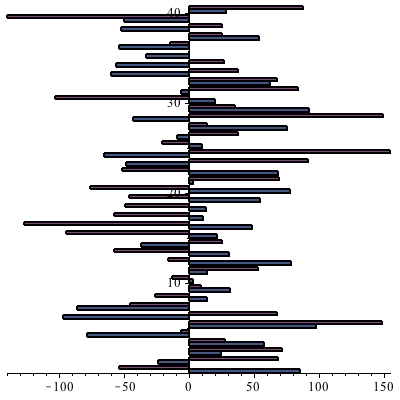
The following graph shows the standard least-squares (red), predictive least-squares (green), and actual numbers on the same plot.
These commands also illustrate another new feature of Maple 17: the output option for sort. It can be used to obtain the reordering applied to the input (in this case, Now we will generate some further data based again on the same hidden indicators, of which only some actually appear as items in the data that we know about.
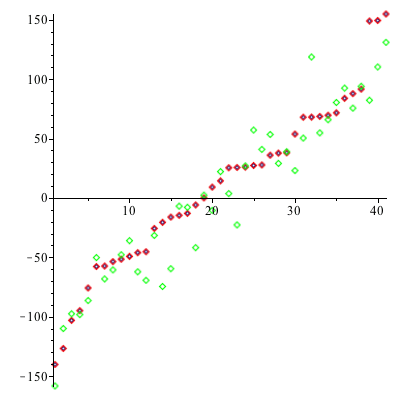
Let's first use the standard least-squares model against the new data.
It is clear that the model suffers from overfitting against spurious parameters in the original data set.
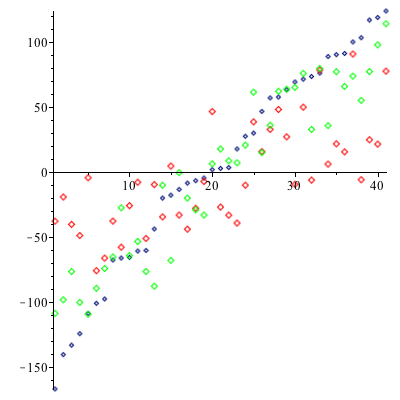
The predictive model achieved a much better correlation when using new data.
It is clear that the predictive least-squares data (green) more closely matches the actual points in black, whereas the standard least-squares data (red), which generally correlates, is much more scattered. A measure of dispersion is a statistic of a data set that describes the variability or spread of that data set. Two well-known examples are the standard deviation and the interquartile range. Maple 17 introduces a new measure of dispersion called Sn, originally proposed by Rousseeuw and Croux [1]. Let us investigate how measures of dispersion behave when noise is added to a data set. Specifically, we will have an original data set
For the standard deviation, we see that changing only one data point can massively change the standard deviation. In other words, there is no positive fraction For the interquartile range, the process is different. Changing a single data point doesn't make the interquartile range of
This suggests that the breakdown point of the interquartile range is The breakdown point for any statistic can never be more than Yes, there are. A relatively well-known one is the median absolute deviation from the median, available in Maple as MedianDeviation. As the name says, it is obtained by computing the absolute difference between every data point and the median of the data set, and taking the median of these values.
The median absolute deviation from the median is a very useful robust estimator, but it also has some disadvantages, explained in the paper [1] by Rousseeuw and Croux. One of their objections is that it doesn't deal with asymmetric distributions very well, and another is that, while it is very robust against extreme changes in some points, it needs relatively many data points to "converge" to the proper value for a distribution in the absence of disturbance. In the statistics literature, this is phrased as saying that the median absolute deviation from the median is not very efficient. These authors propose two alternative statistics that also have a breakdown point of
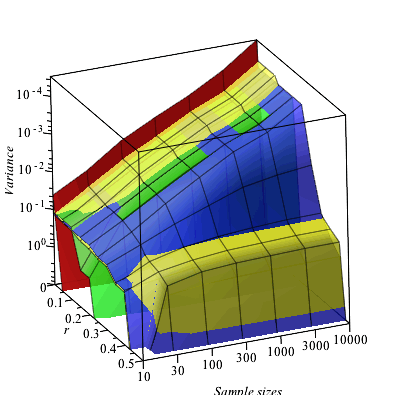
We will show how all of these statistics deviate from their true value for beta-distributed data samples at sample sizes from 10 to 10000 and with fractions between
The colors are red for the standard deviation, green for the interquartile range, blue for the median absolute deviation from the median, and yellow for Rousseeuw and Croux' References
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
](/products/maple/new_features/images17/statistics/Statistics_54.gif)
](/products/maple/new_features/images17/statistics/Statistics_58.gif)
](/products/maple/new_features/images17/statistics/Statistics_69.gif)
](/products/maple/new_features/images17/statistics/Statistics_115.gif)